02 Data and Symbols
This tutorial builds on the introductory tutorial to extend skills in methods of working with and symbolizing vector data within QGIS. After completing this tutorial you will learn how to perform a spatial join and how to manipulate layer symbology based on attribute information.
Deliverables
One map using quantitative symbology to convey information about housing in NYC composed as a 8.5x11 page (landscape or portrait orientation) exported as a PDF. Your map must include standard map elements outlined in the layout portion of this tutorial.
Data
- 2018-2022 American Community Survey, 5 year estimates for housing and tenure variables at the census block level
- 2022 Census blocks for New York City
Please download both datasets from Canvas here in the tutorial 02 folder.
Save them in the data folder that you have created for working on tutorials in this course.
Both datasets are distributed by the IPUMS National Historical Geographic Information System — a great resource for cleaned data from the US census as well as historic census files.
Exercise
Adding data
Open your .qgz file from the introductory tutorial.
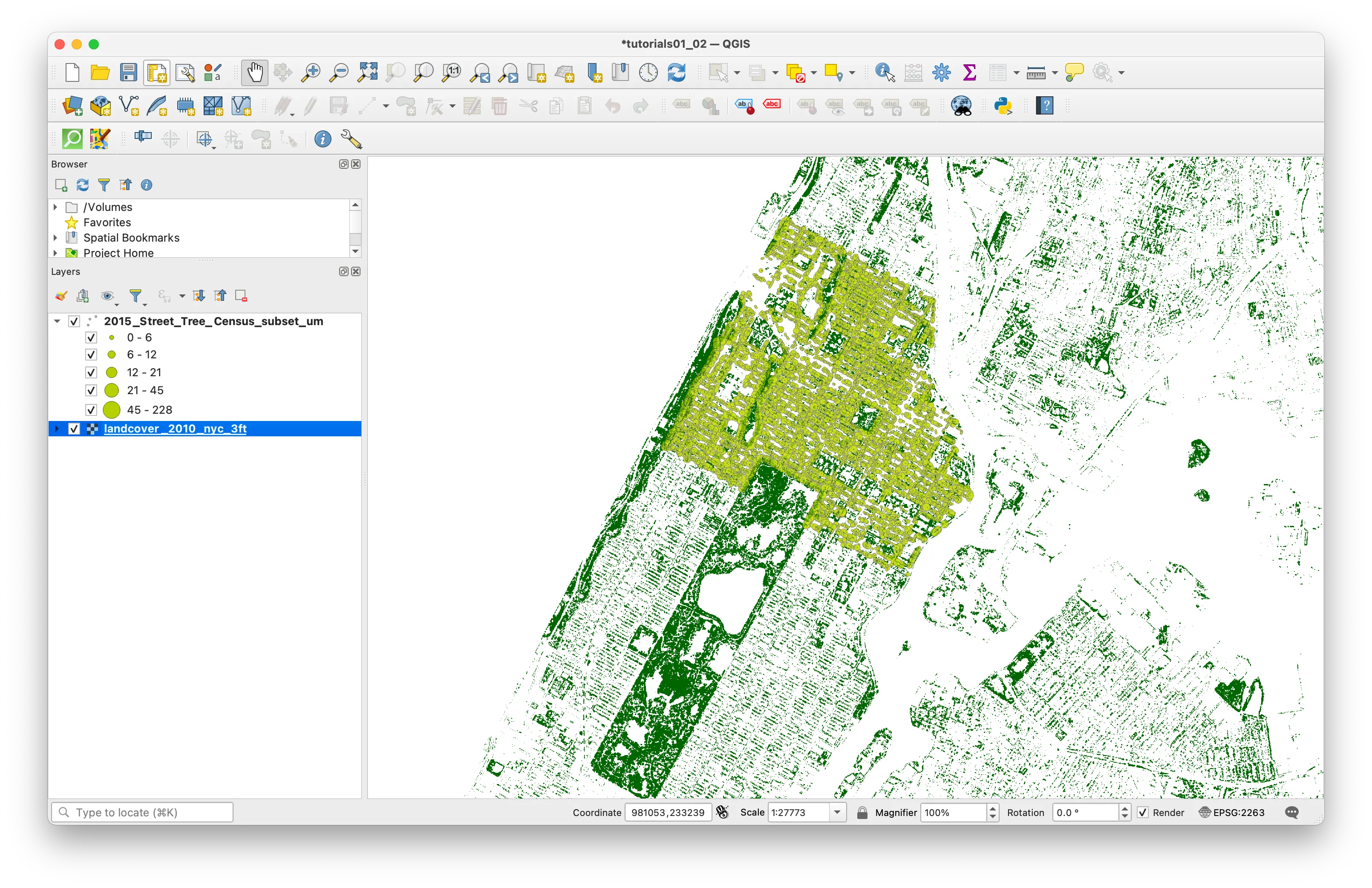
From the top menu bar select Layer and then Add Layer > Add Vector Layer.
When the Data Source Manager menu appears click on the ... and navigate to the data folder for this assignment and add the shapefile of census block groups for New York City that you downloaded above: nyc_block_grp_2022.shp.
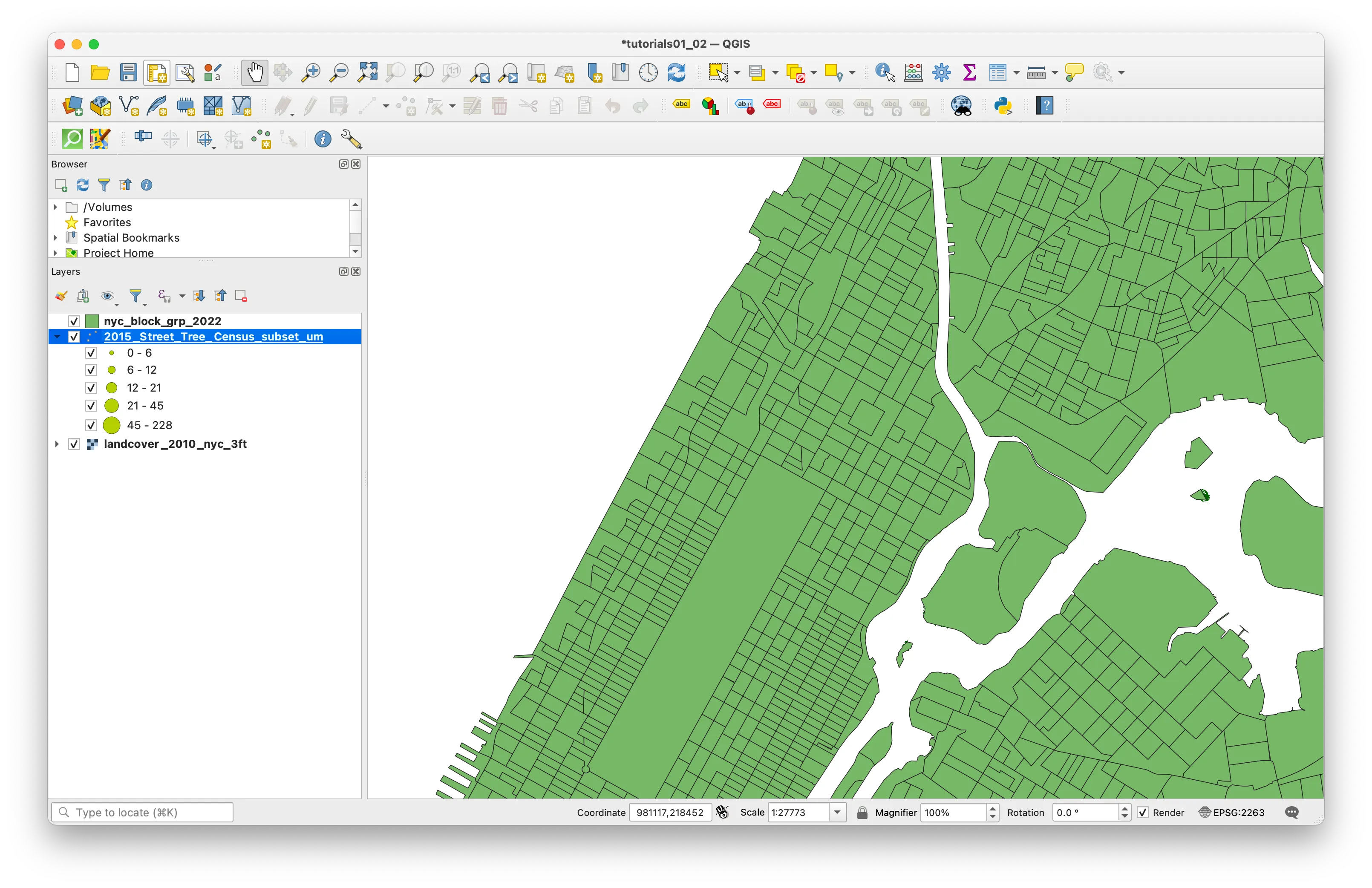
Your project will look something like this.
Open the attribute table for the census block groups you have just added to your project.
You’ll notice there is a lot of identifying information (a GISJOIN field, a GEOID, codes for the state and county of each census block) but there is no other information about demographics or any other information about things going on inside these census block groups. Data is released from the U.S. Census as tabular files “.csv format generally) and in order to visualize information about housing units and rents New York City you must first join this tabular information to the census block groups.
This is something called a table join where we are able to attach additional attribute information to a vector dataset if there is a common identifier field with unique values in the vector dataset and the tabular data with further attribute information.
Next we will add the tabular data containing census information about housing to your project.
Examining metadata
Before you add the table to your QGIS project, take a look at the codebook and metadata included for this dataset: nhgis0012_ds262_20225_blck_grp_codebook.txt. This is generated automatically when you download data from NHGIS and is very helpful for understanding the contents of the data you are about to work with as well as any coded field names.
You’ll see that there is information in this dataset about housing tenure (how many households rent versus own the place that they live), as well as median contract rent, and median gross rent. Notice that AQSQE001 is the field name for the total number of housing units; AQSQE002, is total owner-occupied housing units; and AQSQE003 is the total number of renter-occupied housing units. B25064 is the field that contains values for the median gross rent.
Notice also that there is a field GEOID. This is the unique identifier for each census block group and is the field that you will use to perform a table join between this tabular information about housing, and the census block group geometry.
Now, add the tabular data containing census information about housing to your project.
From the top menu bar select Layer and then Add Layer > Add Delimited Text Layer. Navigate to your data folder and add the nhgis_nyc_20225_blck_grp_housing.csv file. Under the Geometry Definition section select No geometry (attribute only table). Select Add.
Open the attribute table for the census table about housing tenure. Each row contains information about one census block. The TL_GEO_ID field contains unique geographic identifiers for each census block group that are identical to the values in the GEOID field in the census block group vector dataset. This is the field you will use to perform the table join.
Performing a table join
Now that you have added the table of data from the US census about housing we will perform a table join to associate this data with the census block groups it refers to.
By performing a table join we will be able to make a map from data that was previously only available as a table. This is a form of creating spatial data. It is important to note that a table join is a temporary relationship, you are associating information from a table with a vector dataset however you have not done anything to change either of the underlying datasets.
In a table join you are able to append additional attribute information from a table to a vector dataset if two conditions are met:
- there is a common identifier field in the vector dataset and the tabular dataset with further attribute information
- that common identifier field has unique values (i.e. in our case no two census block groups have the same ID)
In a table join there is a target layer and a join layer. The target layer is the layer you are joining information to (in this case the census block group boundary file). The join layer is the layer you are appending information from (in this case the census Housing Tenure table).
You always initiate a table join from the target layer.
To initiate the table join open the Layer Properties menu for the census block vector dataset.
Select the Joins option in the left-hand of the Layer Properties menu. Then select the + icon at the bottom of the menu.
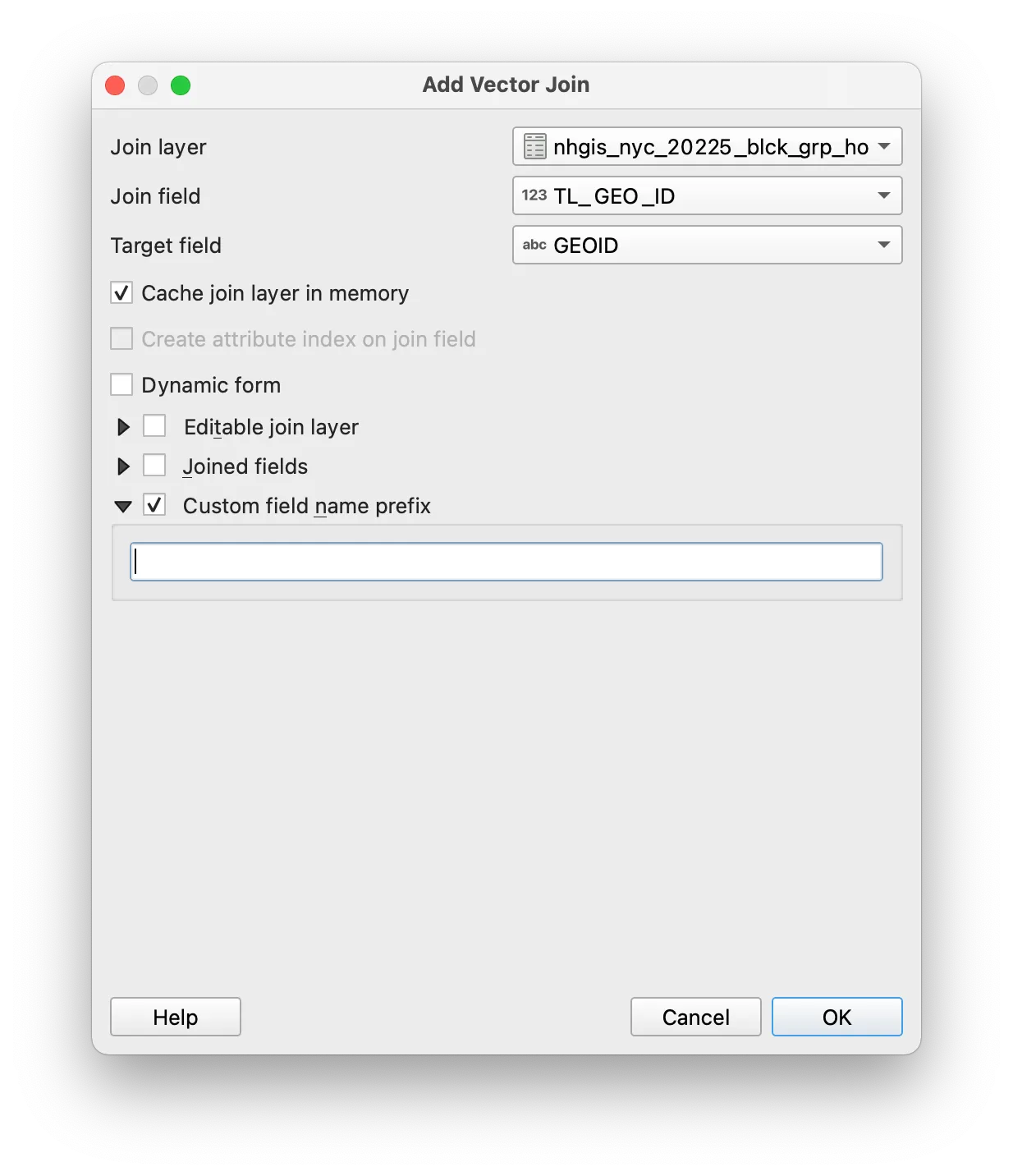
The Add Vector Join menu should appear. Make the selections shown below. Click OK.
To check and see the effect of your table join open the attribute table of the NYC block groups layer. The additional fields from the housing tenure census table should have been added to the attribute table for the NYC block groups boundary file.
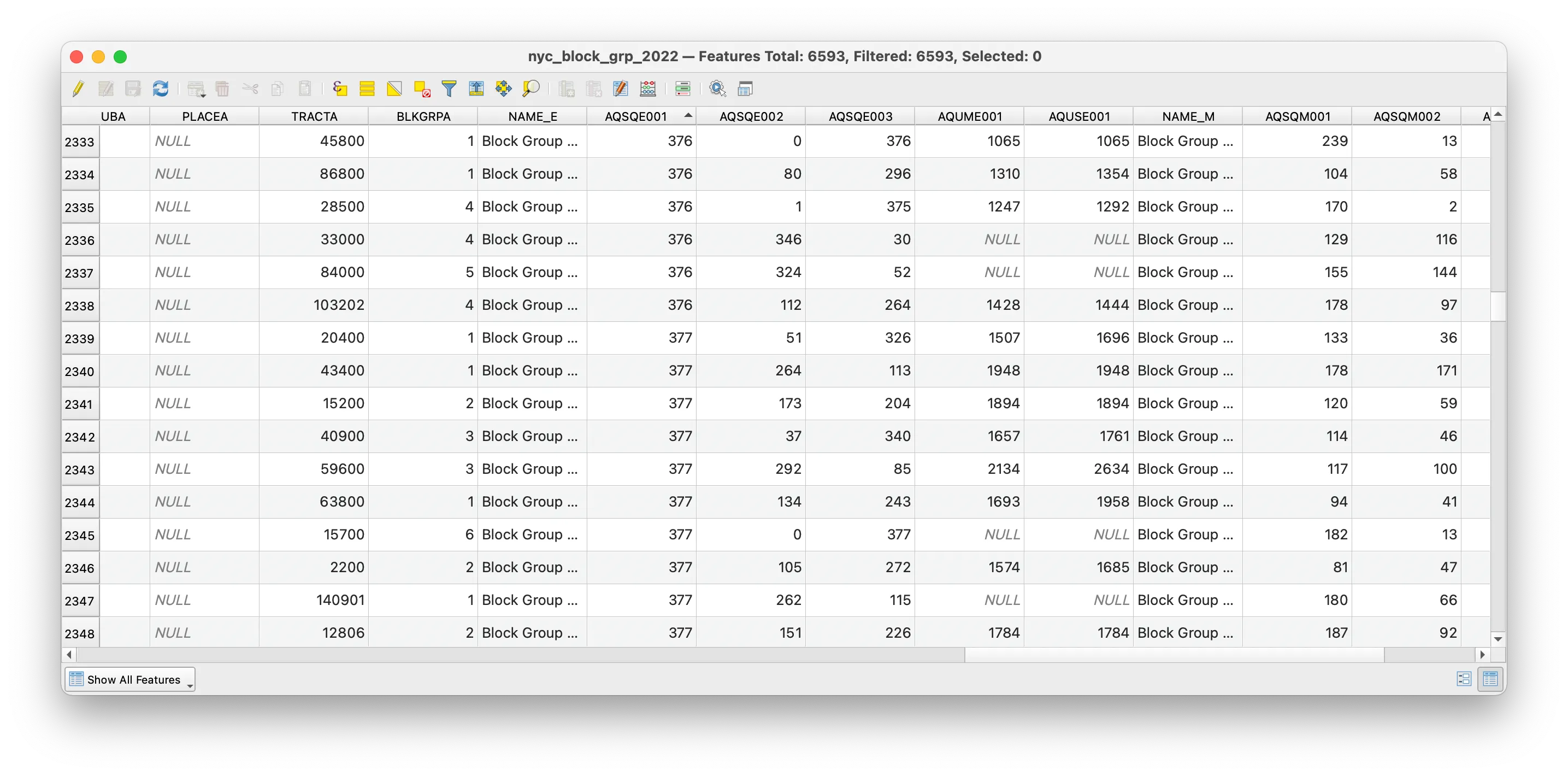
As noted above a table join is a temporary relationship, we have not modified the target layer’s underlying dataset, but are merely looking at an association between two datasets in our QGIS project. To permanently save the table join, we must save a copy of the target layer after we perform the table join.
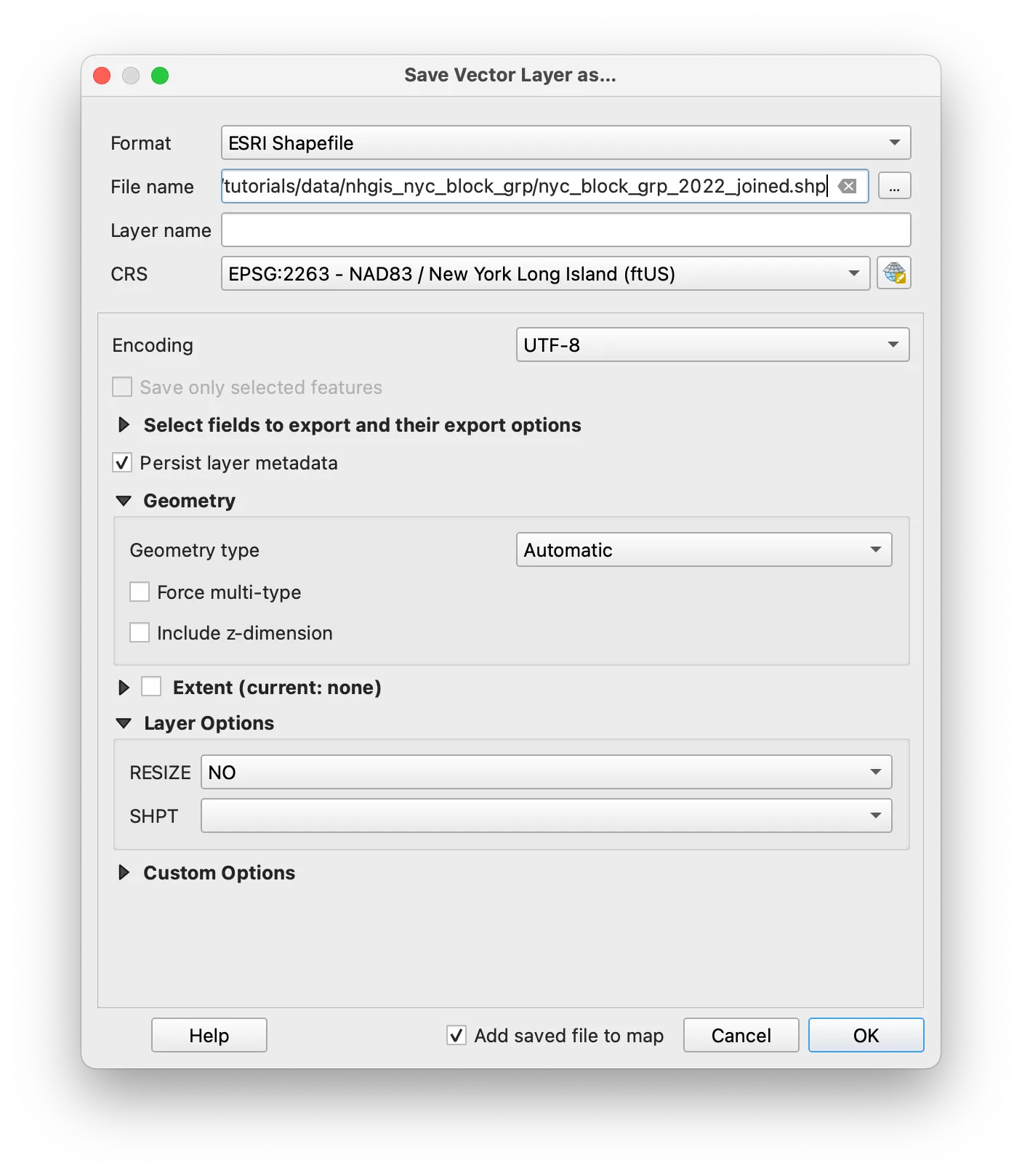
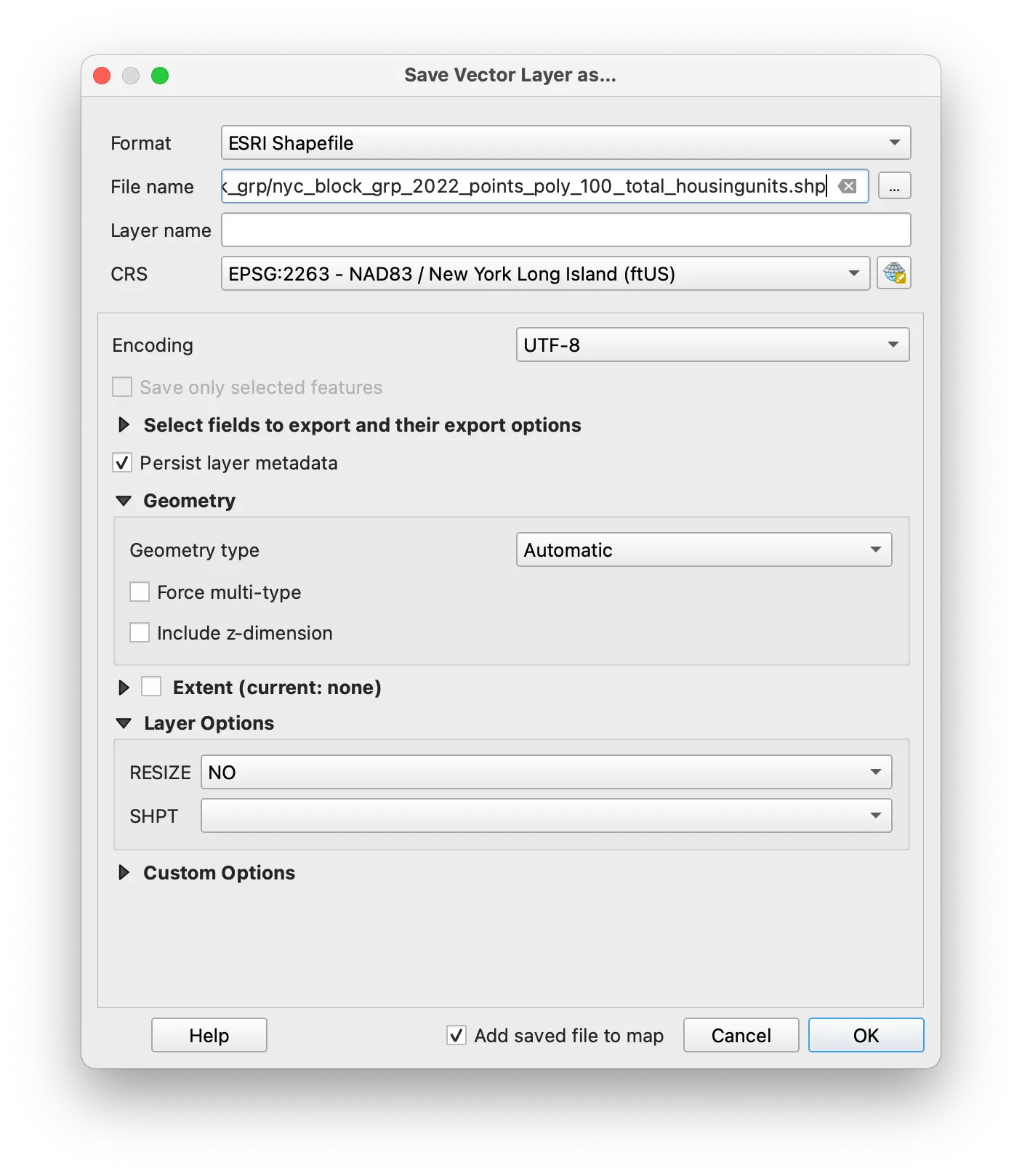
Right click on the NYC block group boundary file and select Export>Save features as to save a new copy of the census block groups that will include the Housing Tenure information we added to the attribute table.
Select ESRI shapefile as the format. Click the button with three dots to the right of the File name field. Navigate to the data folder for your tutorials and save the new file there. Give it a clear file name that conveys how you changed it. nyc_block_grp_2022_joined.shp is a good option.
Remove the other census block group boundary layer, and the Housing Tenure table from the QGIS project, so you just have the nyc_block_grp_2022_joined.shp layer.
Symbolize values
Next you will visualize the housing-related data you have joined to your census block groups in a variety of ways.
The tutorial will walk through three approaches to visualizing quantitative values with vector data:
- a choropleth map of the total number of housing units in each census block group
- a choropleth map showing the percent of renter-occupied housing units in each census block group
- a dot density map showing 1 dot for every 100 housing units within each census block group
Choropleth map of values
Open the Symbology tab. This menu allows you to specify the symbology for this vector dataset.
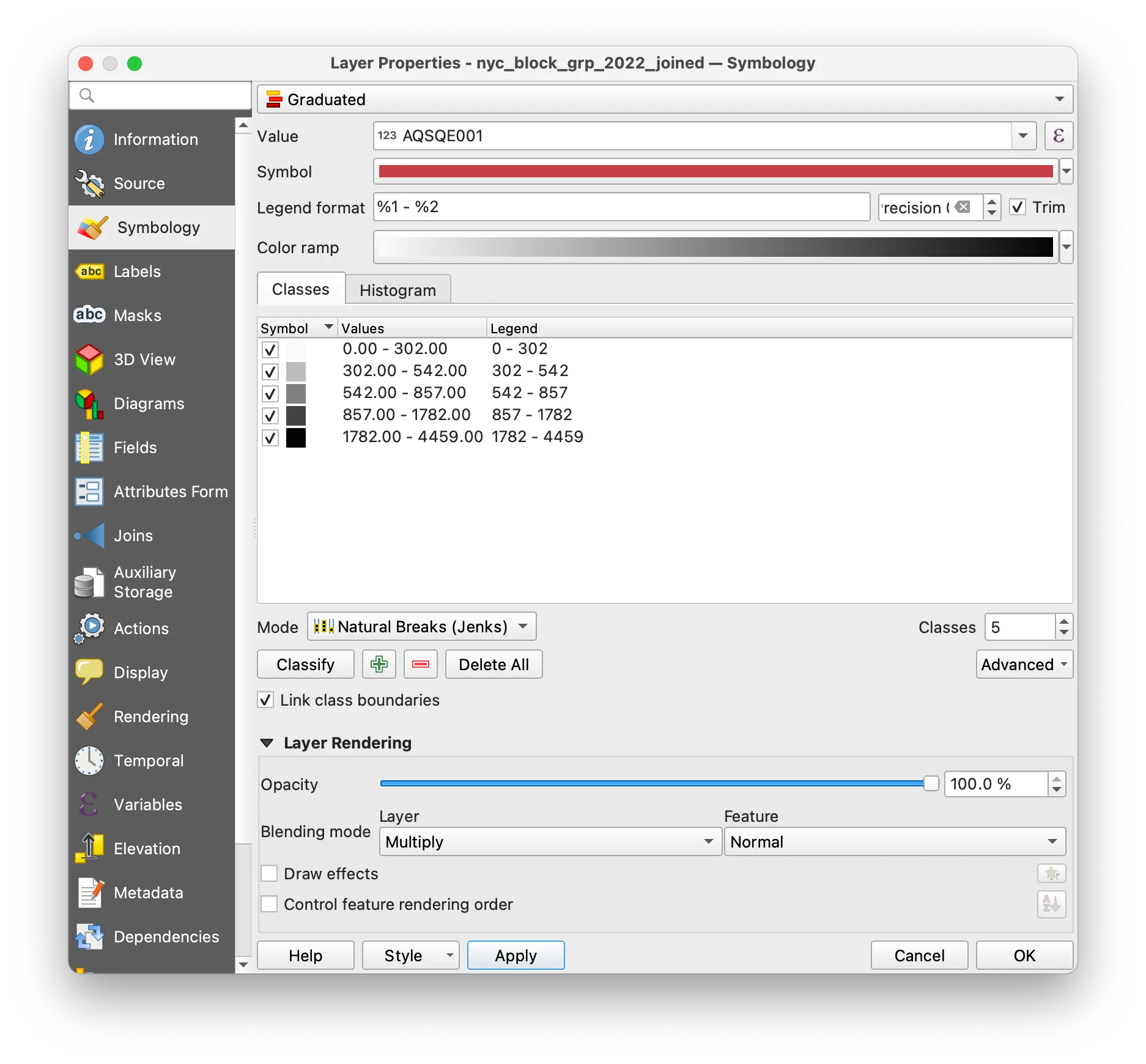
As shown in the screenshot above, select Graduated and then select the field containing values of the total number of housing units for the Value field.
Select Natural Breaks (Jenks) for the Mode and click Classify.
The classification mode determines how your data is grouped and which data values correspond to which colors on your map. The Histogram tab allows you to see the distribution of your data and shows you how the dataset is divided according to the classification scheme you chose. Experiment with changing the classification mode you have chosen and reloading values in the histogram to see how differently they divide your data.
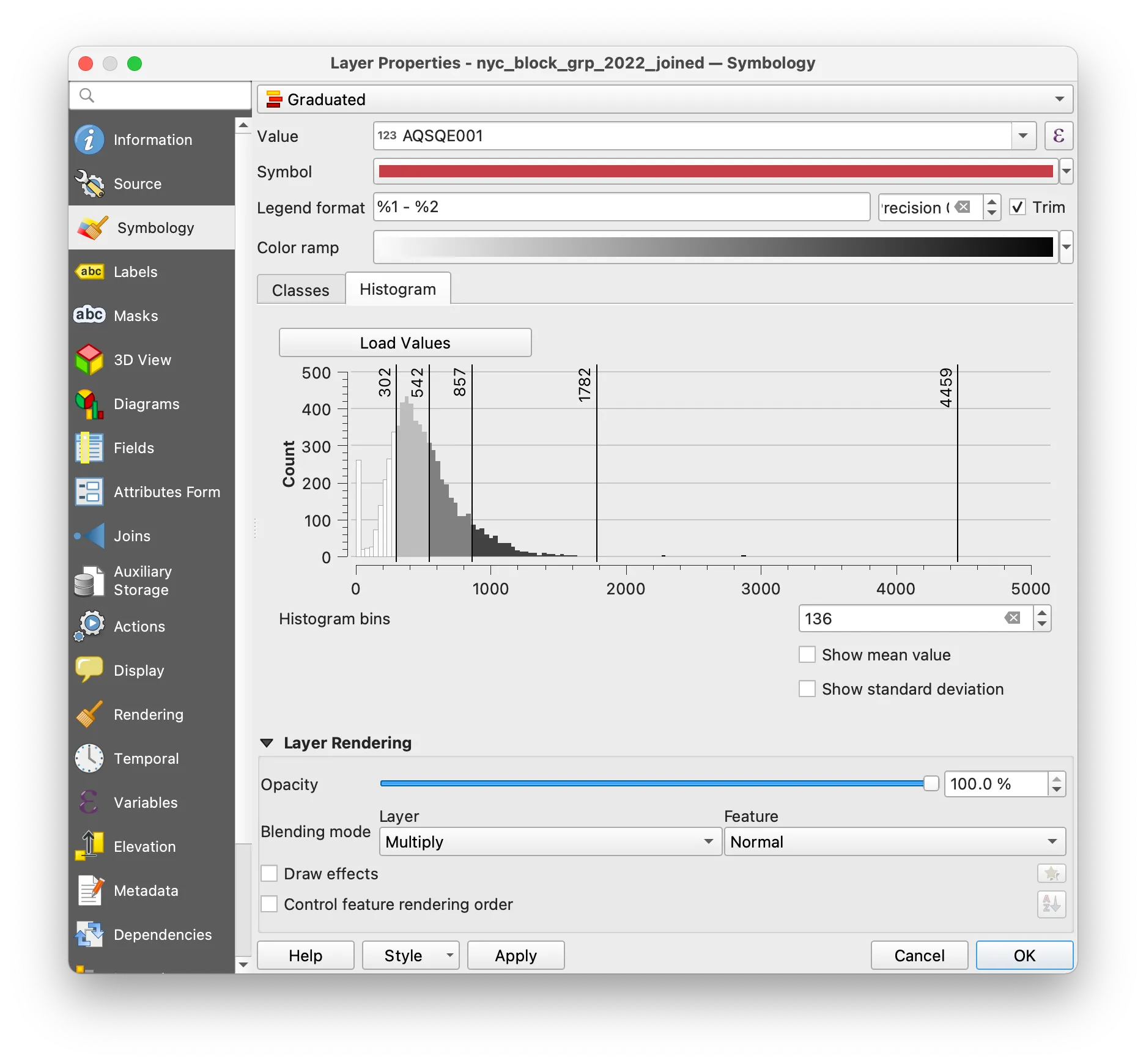
Change the Layer Rendering settings so that you can see the tree canopy raster underneath your census block groups.
Your map should look something like this:
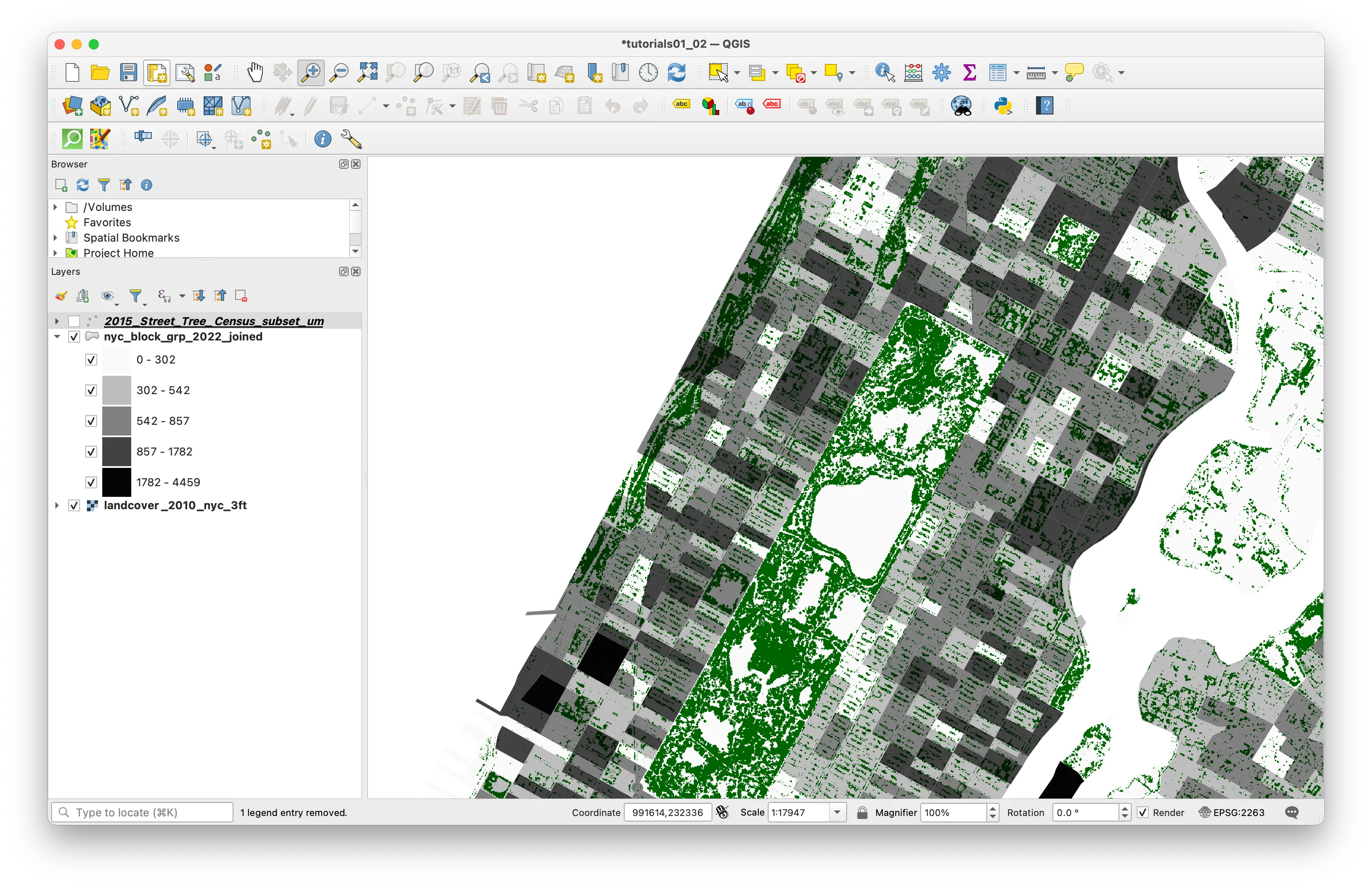
Normalized choropleth map of values
Next you will make a map of the percentage of owner-occupied housing units in each census block group — aka the number of owner-occupied housing units normalized by the total number of housing units in each census block group.
To do this you can either duplicate the NYC block groups layer (so that you retain your the styling and symbology of your total housing units choropleth map) or change the symbology of that layer.
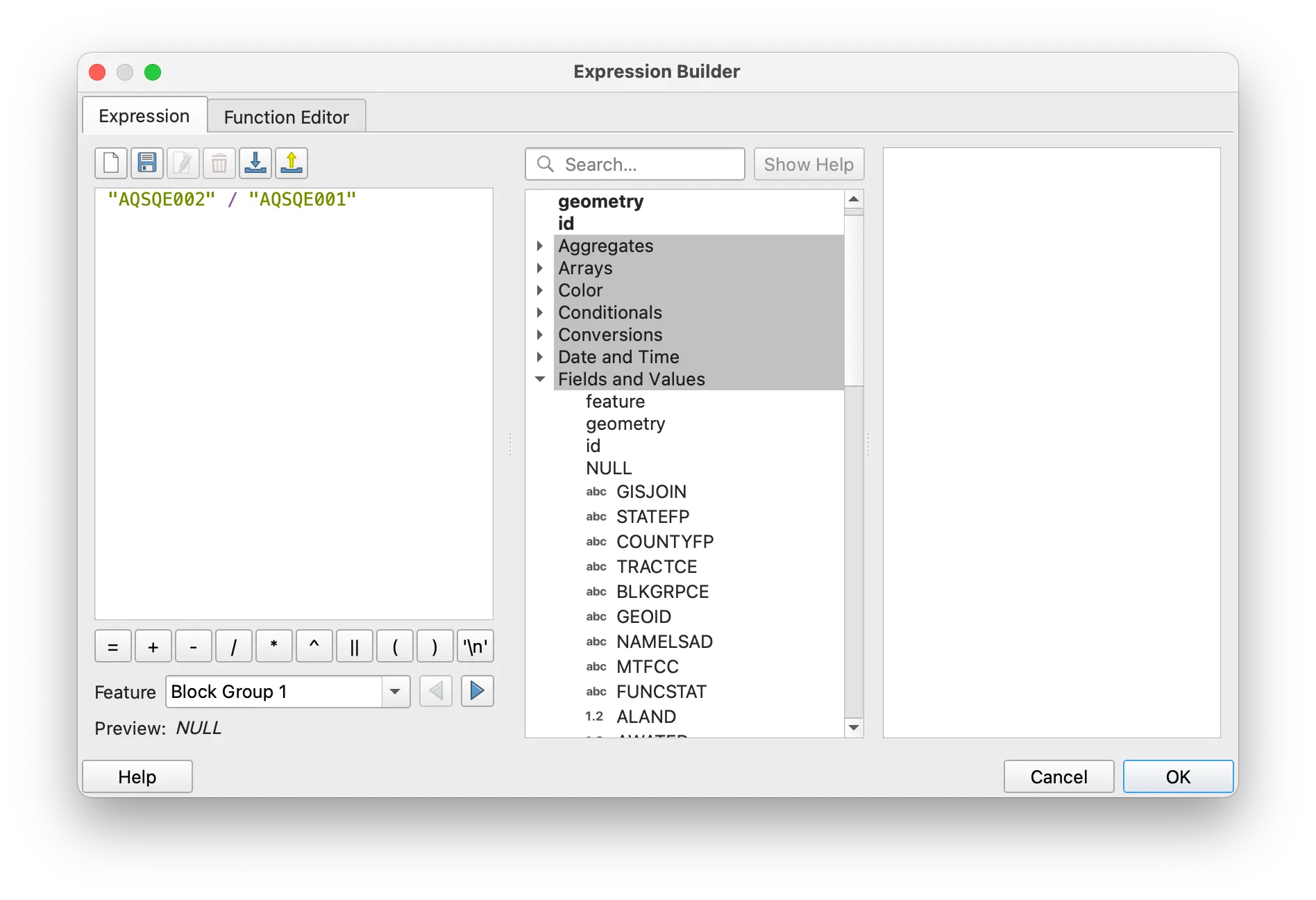
Click on the epsilon button next to the Value field. The Expression Builder should open. In it you can expand the menu for Fields and Values and click on the relevant field names to create the expression on the left. You can also type the expression as shown (using SQL syntax and the correct field names). In the case of this example we are dividing the total number of owner-occupied housing units by the total number of housing units. Click OK.
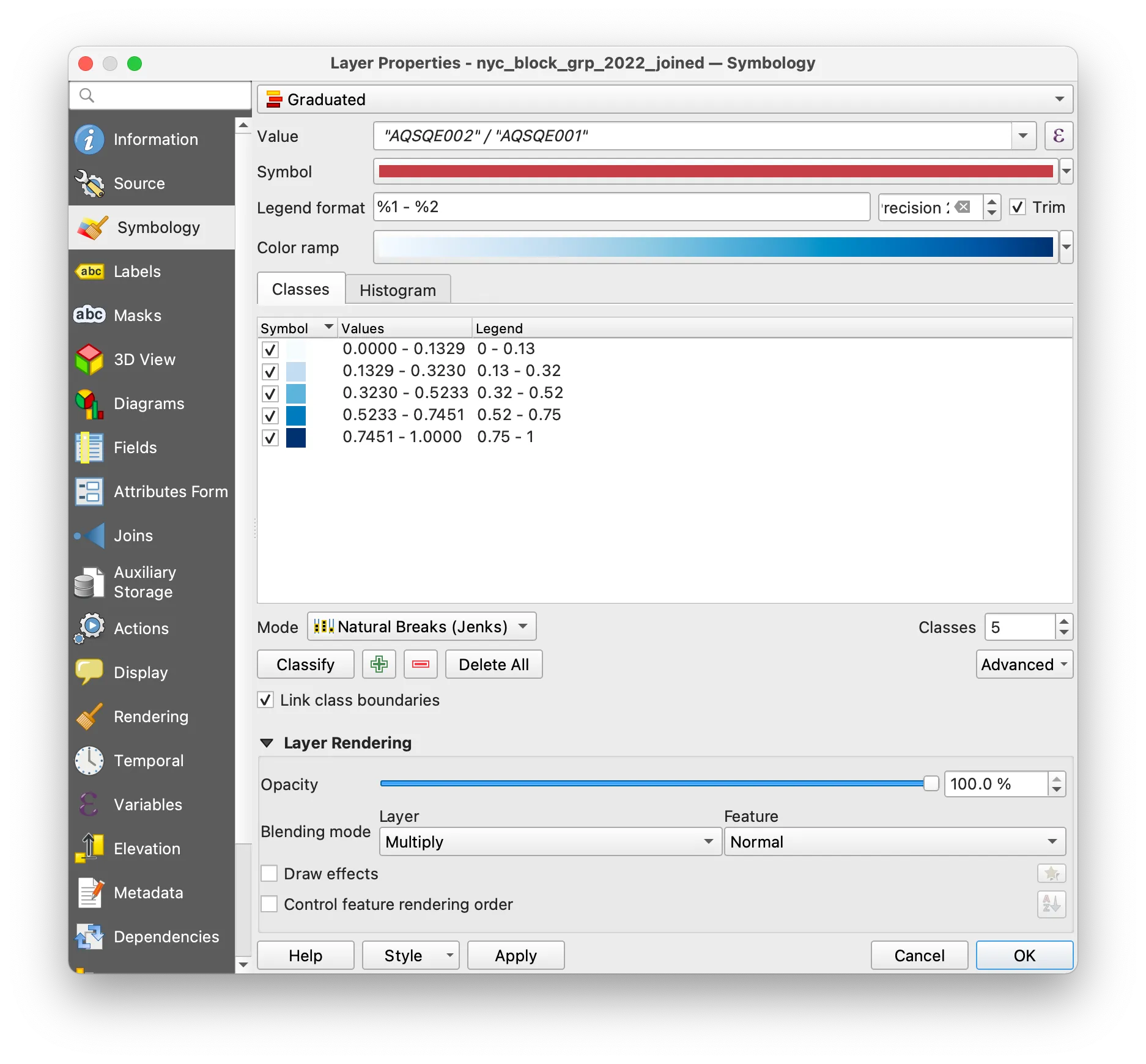
Make your choice of classification mode and color ramp in the Symbology menu. Click OK.
Your map should look something like this:
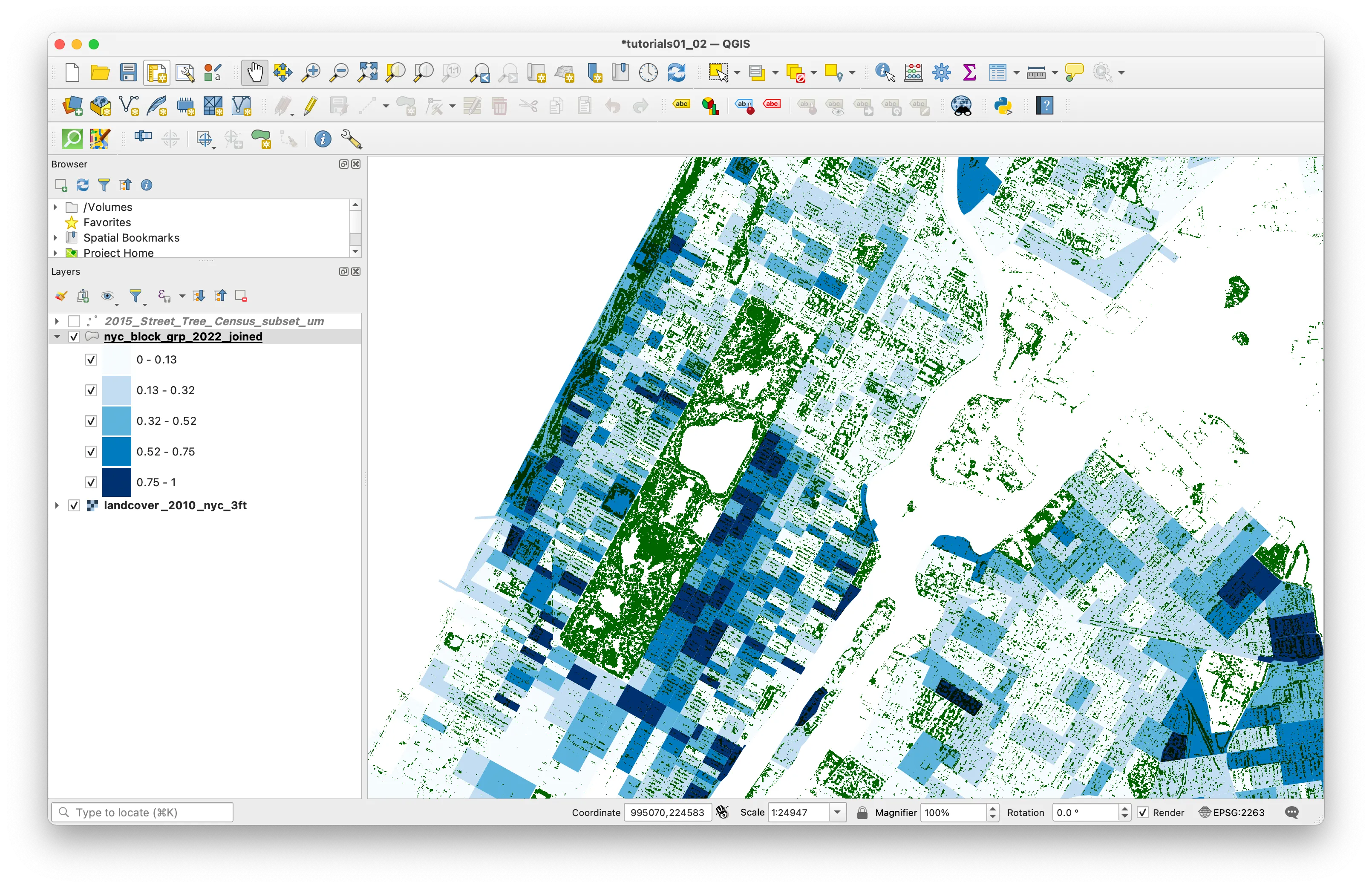
Dot density map
Next you will use a tool from QGIS to generate a dot density map to communicate the number of housing units using a proportional number of dots to the actual number of housing units in the census block.
Dot density maps can be powerful ways to show concentrations in ways that have less emphasis on rigid lines between given boundaries. See this example from cartographer and historian of science Bill Rankin; these from map maker Eric Fischer and this from data visualization expert Jia Zhang.
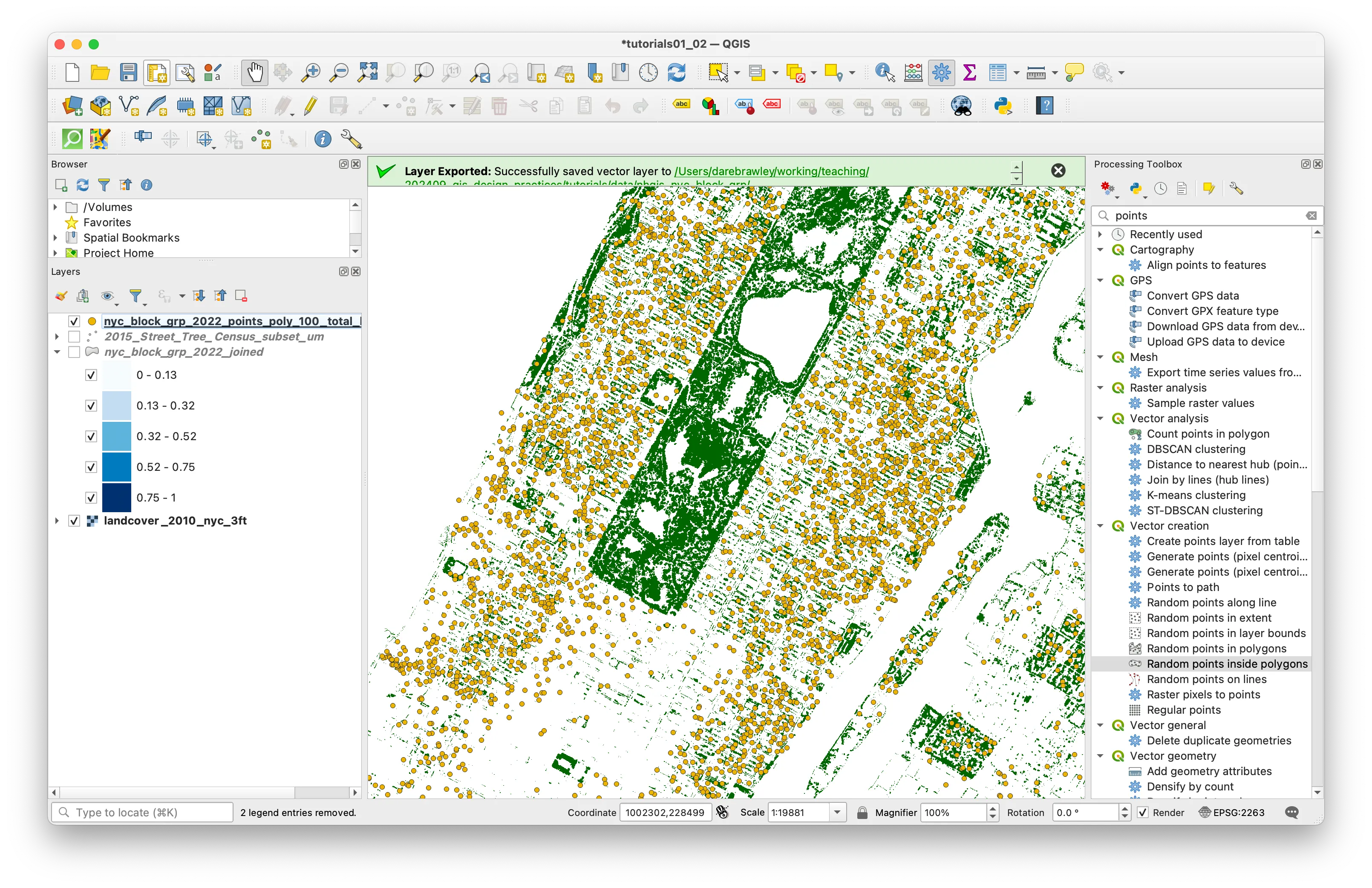
To create a dot density map showing the number of housing units in each census block you will use a tool called Random Points Inside Polygons from the Processing Toolbox. This is a tool that will create a new vector dataset with a specified number of points placed at random locations within given polygons.
If the processing tool box is not already open on your screen you can open it with the gear icon in the top tool panel.
Either search for “Random Points Inside Polygons” or expand the Vector creation section of the processing toolbox.
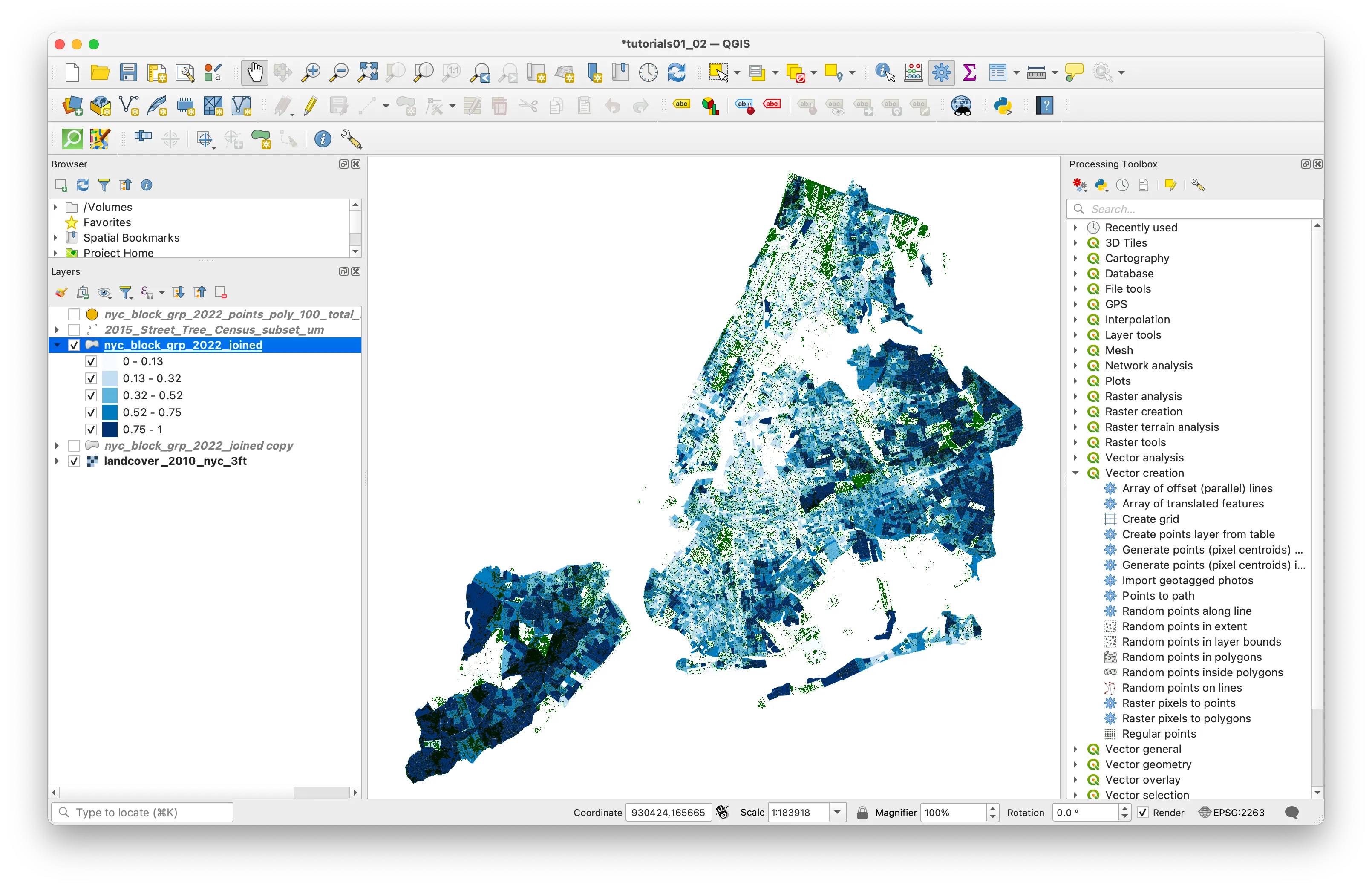
When you open the Random Points Inside Polygons tool select the epsilon button next to the Point count or density field.
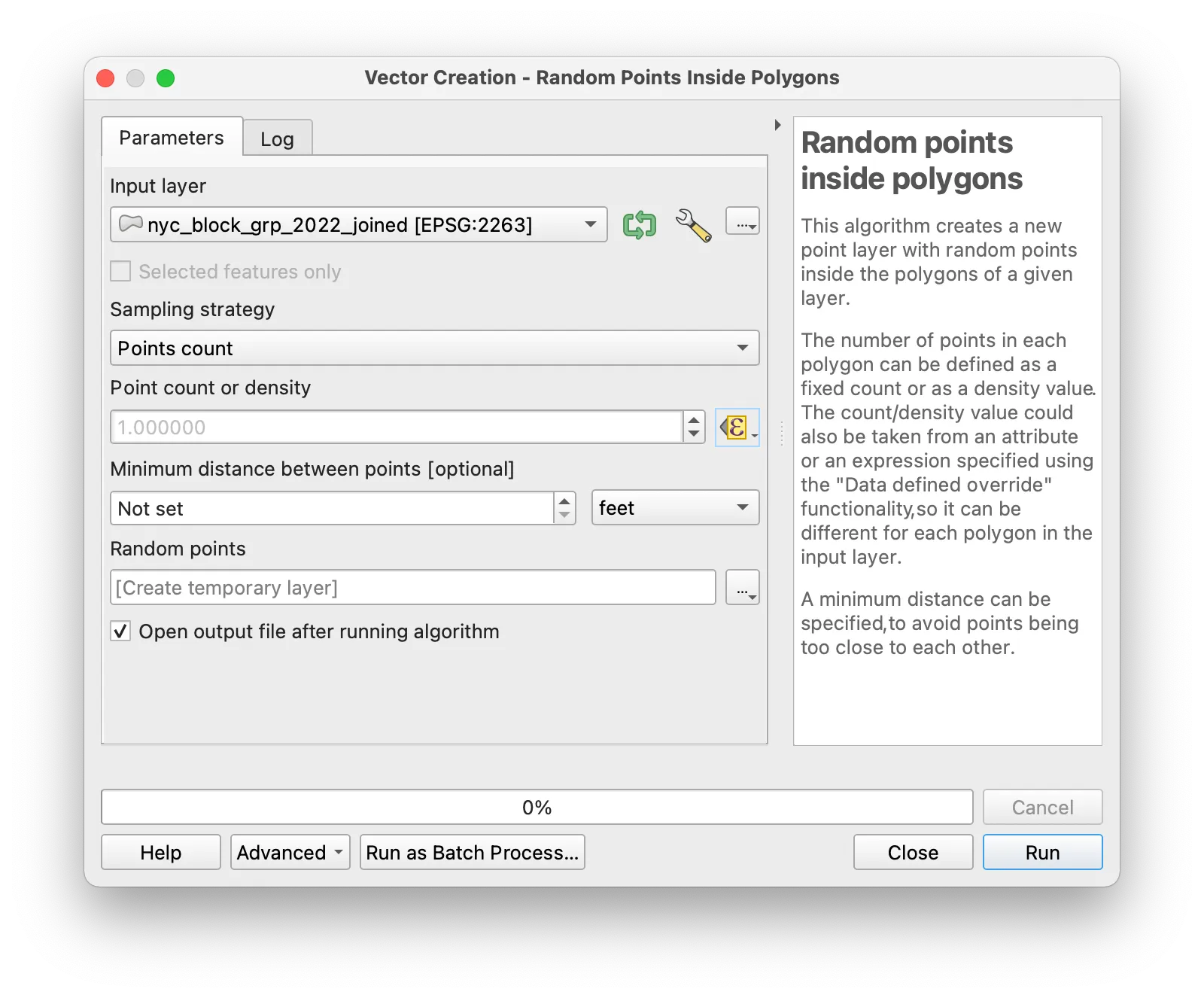
Then with the expression builder select the field from your dataset representing the total number of housing units and divide this number by 100. This will mean that there is 1 dot created for every 100 housing units (you can experiment with different values in the denominator here to get your desired density of dots). Click OK in the Expression Builder. Note that we have not specified a location to save the new vector dataset you are creating (the Random points field states [create temporary layer]. Click Run for the Random Points Inside Polygons tool.
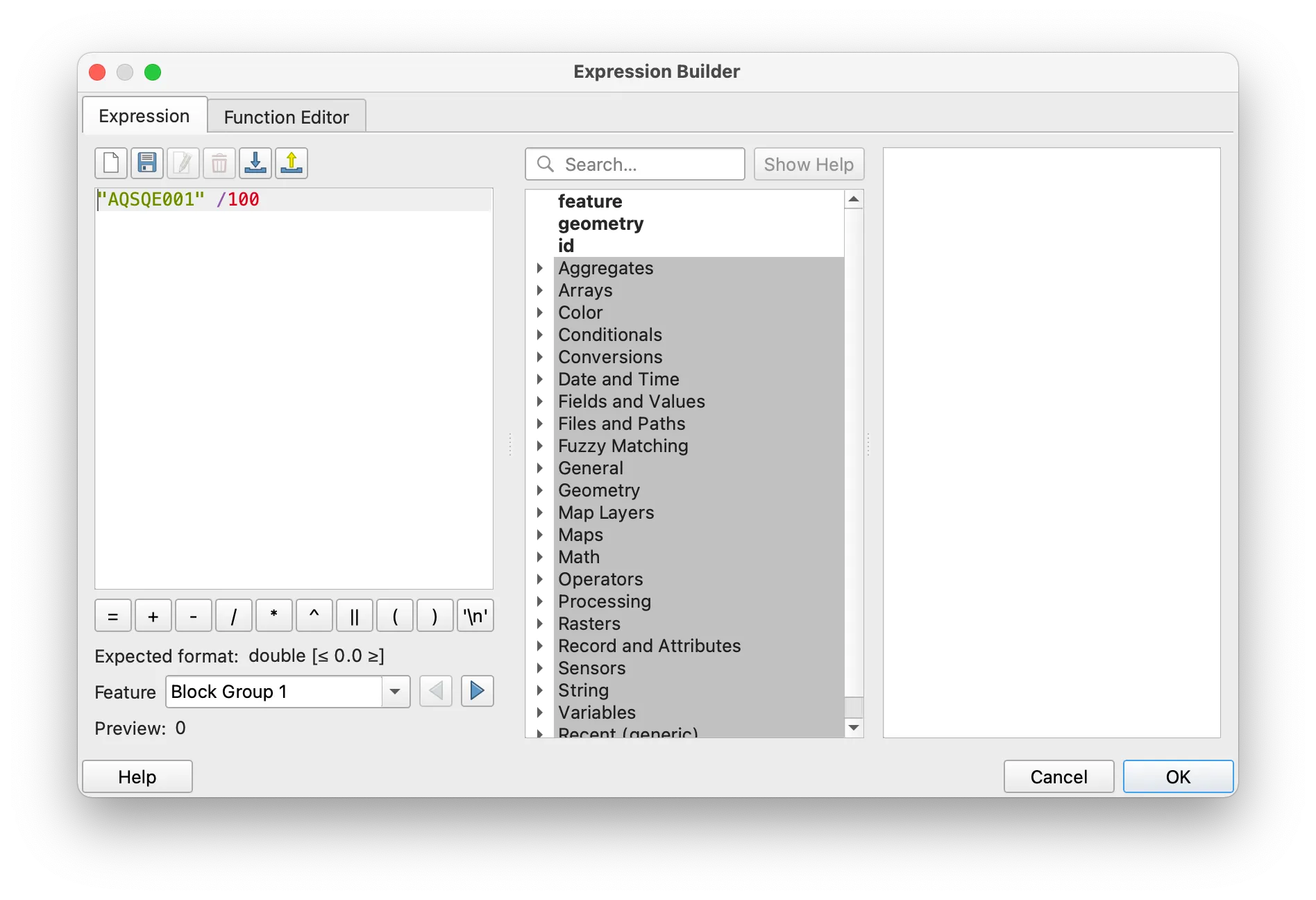
Your map should now look something like this:
When generating the random points we created something called a temporary layer — this is a way to use QGIS to create new datasets but only store them in temporary memory. If you close your QGIS project they will be deleted. This is a helpful feature to avoid producing many datasets while you adjust parameters (such as the number of dots) to obtain your desired result. But once you have a result you are happy with to retain the data after closing your QGIS project you must export the layer to save it as a new vector dataset.
To do this right click on the Random points layer in the layers panel that you would like to save. And select Export>Save features as. Click on the ... button to specify a location to save your new dataset and give it a name. Specify the coordinate reference system you would live to save the file with (you should use EPSG: 2263 for any maps of NYC). Check the box next to Add saved file to map. Click OK
Your new vector dataset of points representing the number of housing units in each census block group in New York City should now be added to the map.
Now experiment with any of the above symbology methods to create a map of your choice expressing something about housing in NYC. Create a print layout with a legend and key map elements and export a PDF of your map.
Upload one map to canvas that uses quantitative symbology to convey information about housing in NYC composed as a 8.5x11 page (landscape or portrait orientation) exported as a PDF. Your map must include standard map elements outlined in the layout portion of tutorial 01.